Onboarding first version of systems_design
This commit is contained in:
commit
c9686ceae4
|
|
@ -0,0 +1,88 @@
|
|||
## HA - Availability - Common “Nines”
|
||||
Availability is generally expressed as “Nines”, common ‘Nines’ are listed below.
|
||||
|
||||
| Availability % | Downtime per year | Downtime per month | Downtime per week | Downtime per day |
|
||||
|---------------------------------|:-----------------:|:-------------------:|:-----------------:|:----------------:|
|
||||
| 99%(Two Nines) | 3.65 days | 7.31 hours | 1.68 hours | 14.40 minutes |
|
||||
| 99.5%(Two and a half Nines) | 1.83 days | 3.65 hours | 50.40 minutes | 7.20 minutes |
|
||||
| 99.9%(Three Nines) | 8.77 hours | 43.83 minutes | 10.08 minutes | 1.44 minutes |
|
||||
| 99.95%(Three and a half Nines) | 4.38 hours | 21.92 minutes | 5.04 minutes | 43.20 seconds |
|
||||
| 99.99%(Four Nines) | 52.60 minutes | 4.38 minutes | 1.01 minutes | 8.64 seconds |
|
||||
| 99.995%(Four and a half Nines) | 26.30 minutes | 2.19 minutes | 30.24 seconds | 4.32 seconds |
|
||||
| 99.999%(Five Nines) | 5.26 minutes | 26.30 seconds | 6.05 seconds | 864.0 ms |
|
||||
|
||||
### Refer
|
||||
- https://en.wikipedia.org/wiki/High_availability#Percentage_calculation
|
||||
|
||||
## HA - Availability Serial Components
|
||||
|
||||
A System with components is operating in the series If failure of a part leads to the combination becoming inoperable.
|
||||
|
||||
For example if LB in our architecture fails, all access to app tiers will fail. LB and app tiers are connected serially.
|
||||
|
||||
|
||||
The combined availability of the system is the product of individual components availability
|
||||
|
||||
*A = Ax x Ay x …..*
|
||||
|
||||
### Refer
|
||||
- http://www.eventhelix.com/RealtimeMantra/FaultHandling/system_reliability_availability.htm
|
||||
|
||||
## HA - Availability Parallel Components
|
||||
|
||||
A System with components is operating in parallel If failure of a part leads to the other part taking over the operations of the failed part.
|
||||
|
||||
If we have more than one LB and if rest of the LBs can take over the traffic during one LB failure then LBs are operating in parallel
|
||||
|
||||
The combined availability of the system is
|
||||
|
||||
*A = 1 - ( (1-Ax) x (1-Ax) x ….. )*
|
||||
|
||||
### Refer
|
||||
- http://www.eventhelix.com/RealtimeMantra/FaultHandling/system_reliability_availability.htm
|
||||
|
||||
## HA - Core Principles
|
||||
|
||||
**Elimination of single points of failure (SPOF)** This means adding redundancy to the system so that the failure of a component does not mean failure of the entire system.
|
||||
|
||||
**Reliable crossover** In redundant systems, the crossover point itself tends to become a single point of failure. Reliable systems must provide for reliable crossover.
|
||||
|
||||
**Detection of failures as they occur** If the two principles above are observed, then a user may never see a failure
|
||||
|
||||
### Refer
|
||||
- https://en.wikipedia.org/wiki/High_availability#Principles
|
||||
|
||||
## HA - SPOF
|
||||
|
||||
**WHAT:** Never implement and always eliminate single points of failure.
|
||||
|
||||
**WHEN TO USE:** During architecture reviews and new designs.
|
||||
|
||||
**HOW TO USE:** Identify single instances on architectural diagrams. Strive for active/active configurations. At the very least we should have a standby to take control when active instances fail.
|
||||
|
||||
**WHY:** Maximize availability through multiple instances.
|
||||
|
||||
**KEY TAKEAWAYS:** Strive for active/active rather than active/passive solutions. Use load balancers to balance traffic across instances of a service. Use control services with active/passive instances for patterns that require singletons.
|
||||
|
||||
## HA - Reliable Crossover
|
||||
|
||||
**WHAT:** Ensure when system components failover they do so reliably.
|
||||
|
||||
**WHEN TO USE:** During architecture reviews, failure modeling, and designs.
|
||||
|
||||
**HOW TO USE:** Identify how available a system is during the crossover and ensure it is within acceptable limits.
|
||||
|
||||
**WHY:** Maximize availability and ensure data handling semantics are preserved.
|
||||
|
||||
**KEY TAKEAWAYS:** Strive for active/active rather than active/passive solutions, they have a lesser risk of cross over being unreliable. Use LB and right load balancing methods to ensure reliable failover. Model and build your data systems to ensure data is correctly handled when crossover happens. Generally DB systems follow active/passive semantics for writes. Masters accept writes and when master goes down, follower is promoted to master(active from being passive) to accept writes. We have to be careful here that the cutover never introduces more than one masters. This problem is called a split brain.
|
||||
|
||||
## SRE Use cases
|
||||
1. SRE works on deciding an acceptable SLA and make sure system is available to achieve the SLA
|
||||
2. SRE is involved in architecture design right from building the data center to make sure site is not affected by network switch, hardware, power or software failures
|
||||
3. SRE also run mock drills of failures to see how the system behaves in uncharted territory and comes up with a plan to improve availability if there are misses.
|
||||
https://engineering.linkedin.com/blog/2017/11/resilience-engineering-at-linkedin-with-project-waterbear
|
||||
|
||||
|
||||
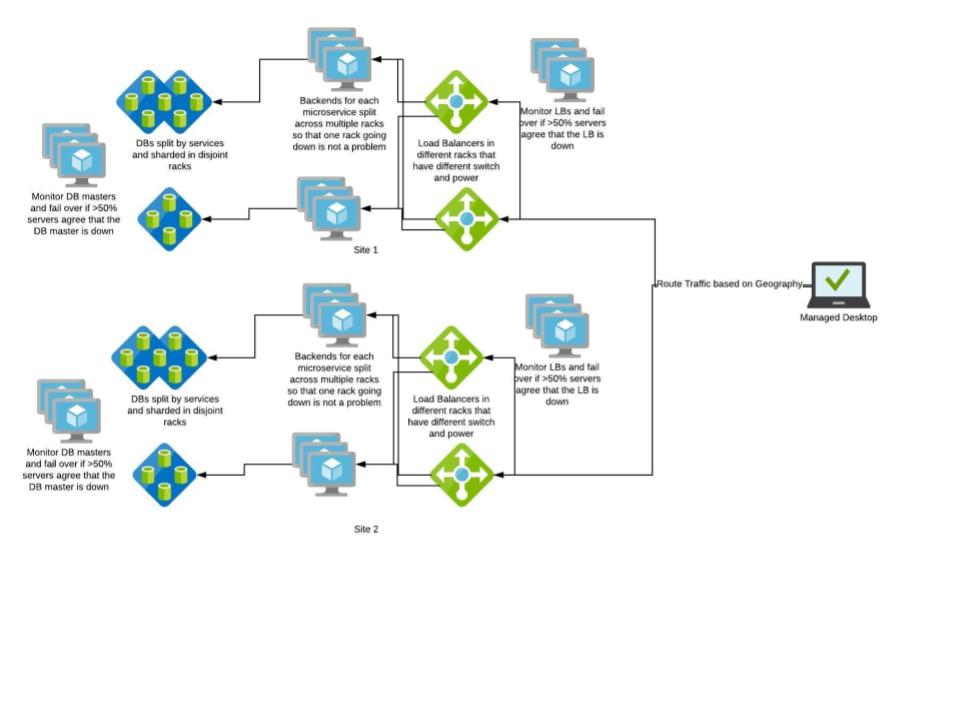
Post our understanding about HA, our architecture diagram looks something like this below
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,3 @@
|
|||
## Conclusion
|
||||
|
||||
Armed with these principles, we hope the course will give a fresh perspective to design software systems. It might be over engineering to get all this on day zero. But some are really important from day 0 like eliminating single points of failure, making scalable services by just increasing replicas. As a bottleneck is reached, we can split code by services, shard data to scale. As the organisation matures, bringing in [chaos engineering](https://en.wikipedia.org/wiki/Chaos_engineering) to measure how systems react to failure will help in designing robust software systems.
|
||||
|
|
@ -0,0 +1,68 @@
|
|||
## Fault Tolerance
|
||||
|
||||
Failures are not avoidable in any system and will happen all the time, hence we need to build systems that can tolerate failures or recover from them.
|
||||
|
||||
- In systems, failure is the norm rather than the exception.
|
||||
- "Anything that can go wrong will go wrong” -- Murphy’s Law
|
||||
- “Complex systems contain changing mixtures of failures latent within them” -- How Complex Systems Fail.
|
||||
|
||||
### Fault Tolerance - Failure Metrics
|
||||
|
||||
Common failure metrics that get measured and tracked for any system.
|
||||
|
||||
**Mean time to repair (MTTR):** The average time to repair and restore a failed system.
|
||||
|
||||
**Mean time between failures (MTBF):** The average operational time between one device failure or system breakdown and the next.
|
||||
|
||||
**Mean time to failure (MTTF):** The average time a device or system is expected to function before it fails.
|
||||
|
||||
**Mean time to detect (MTTD):** The average time between the onset of a problem and when the organization detects it.
|
||||
|
||||
**Mean time to investigate (MTTI):** The average time between the detection of an incident and when the organization begins to investigate its cause and solution.
|
||||
|
||||
**Mean time to restore service (MTRS):** The average elapsed time from the detection of an incident until the affected system or component is again available to users.
|
||||
|
||||
**Mean time between system incidents (MTBSI):** The average elapsed time between the detection of two consecutive incidents. MTBSI can be calculated by adding MTBF and MTRS (MTBSI = MTBF + MTRS).
|
||||
|
||||
**Failure rate:** Another reliability metric, which measures the frequency with which a component or system fails. It is expressed as a number of failures over a unit of time.
|
||||
|
||||
#### Refer
|
||||
- https://www.splunk.com/en_us/data-insider/what-is-mean-time-to-repair.html
|
||||
|
||||
### Fault Tolerance - Fault Isolation Terms
|
||||
Systems should have a short circuit. Say in our content sharing system, if “Notifications” is not working, the site should gracefully handle that failure by removing the functionality instead of taking the whole site down.
|
||||
|
||||
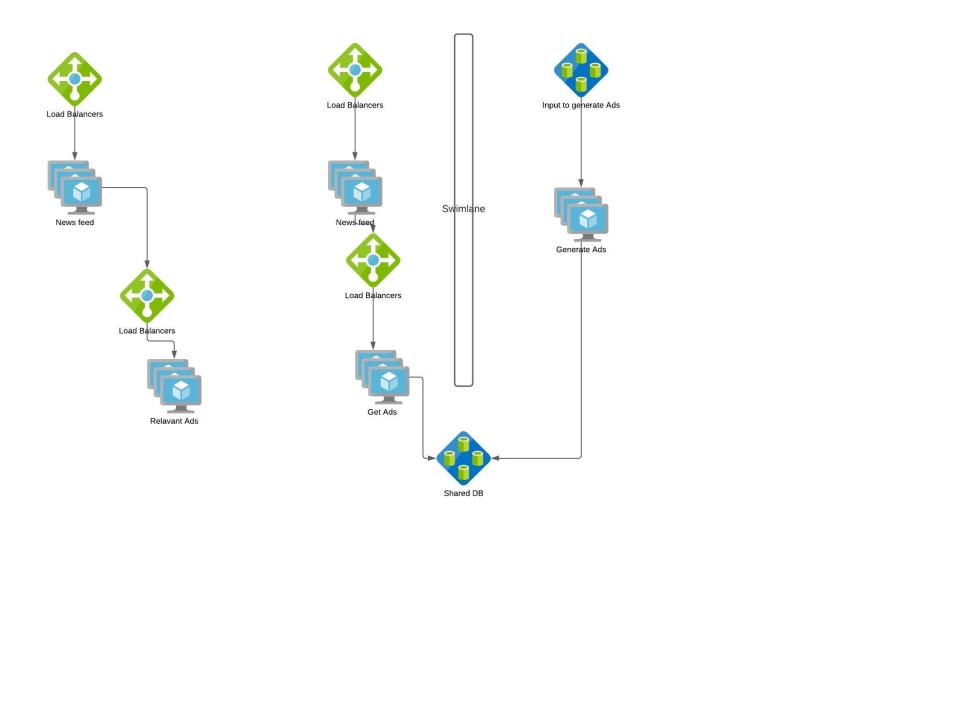
Swimlane is one of the commonly used fault isolation methodology. Swimlane adds a barrier to the service from other services so that failure on either of them won’t affect the other. Say we roll out a new feature ‘Advertisement’ in our content sharing app.
|
||||
We can have two architectures
|
||||
|
||||
|
||||
If Ads are generated on the fly synchronously during each Newsfeed request, the faults in Ads feature gets propagated to Newsfeed feature. Instead if we swimlane “Generation of Ads” service and use a shared storage to populate Newsfeed App, Ads failures won’t cascade to Newsfeed and worst case if Ads don’t meet SLA , we can have Newsfeed without Ads.
|
||||
|
||||
Let's take another example, we come up with a new model for our Content sharing App. Here we roll out enterprise content sharing App where enterprises pay for the service and the content should never be shared outside the enterprise.
|
||||
|
||||
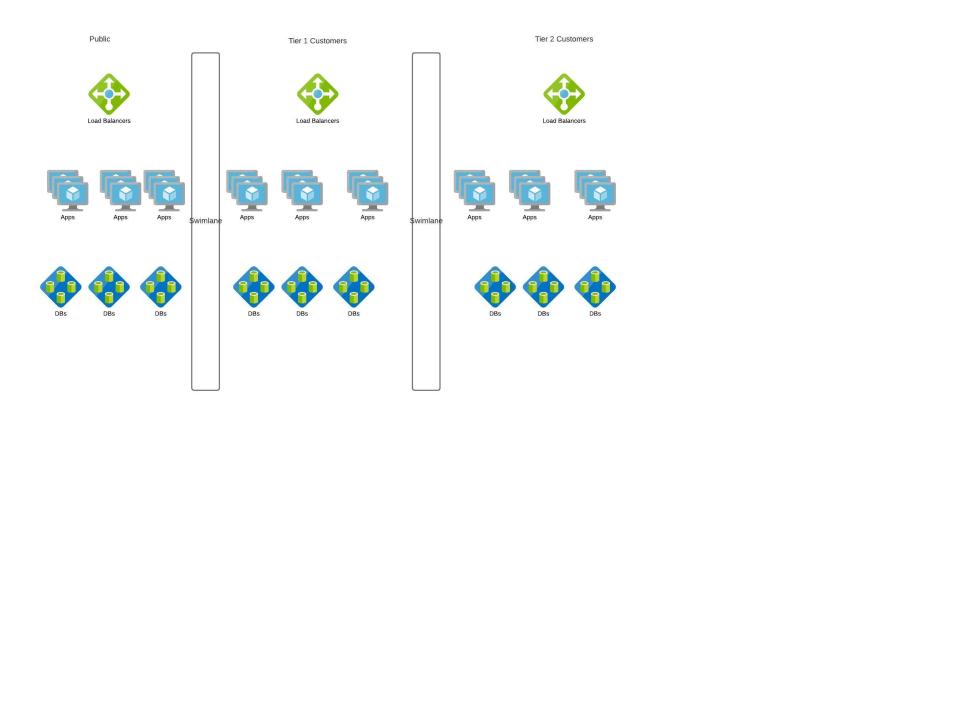
|
||||
|
||||
### Swimlane Principles
|
||||
|
||||
**Principle 1:** Nothing is shared (also known as “share as little as possible”). The less that is shared within a swim lane, the more fault isolative the swim lane becomes. (as shown in Enterprise usecase)
|
||||
|
||||
**Principle 2:** Nothing crosses a swim lane boundary. Synchronous (defined by expecting a request—not the transfer protocol) communication never crosses a swim lane boundary; if it does, the boundary is drawn incorrectly. (as shown in Ads feature)
|
||||
|
||||
### Swimlane Approaches
|
||||
**Approach 1:** Swim lane the money-maker. Never allow your cash register to be compromised by other systems. (Tier 1 vs Tier 2 in enterprise use case)
|
||||
|
||||
**Approach 2:** Swim lane the biggest sources of incidents. Identify the recurring causes of pain and isolate them.(if Ads feature is in code yellow, swim laning it is the best option)
|
||||
|
||||
**Approach 3:** Swim lane natural barriers. Customer boundaries make good swim lanes.(Public vs Enterprise customers)
|
||||
|
||||
|
||||
#### Refer
|
||||
- https://learning.oreilly.com/library/view/the-art-of/9780134031408/ch21.html#ch21
|
||||
|
||||
|
||||
### SRE Use cases:
|
||||
1. Work with the DC tech or cloud team to distribute infrastructure such that its immune to switch or power failures by creating fault zones within a Data Center
|
||||
https://docs.microsoft.com/en-us/azure/virtual-machines/manage-availability#use-availability-zones-to-protect-from-datacenter-level-failures
|
||||
2. Work with the partners and design interaction between services such that one service breakdown is not amplified in a cascading fashion to all upstreams
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,46 @@
|
|||
# Systems Design
|
||||
|
||||
## Pre - Requisites
|
||||
|
||||
Fundamentals of common software system components:
|
||||
- Operating Systems
|
||||
- Networking
|
||||
- Databases RDBMS/NoSQL
|
||||
|
||||
## What to expect from this training
|
||||
|
||||
Thinking about and designing for scalability, availability, and reliability of large scale software systems.
|
||||
|
||||
## What is not covered under this training
|
||||
|
||||
Individual software components’ scalability and reliability concerns like e.g. Databases, while the same scalability principles and thinking can be applied, these individual components have their own specific nuances when scaling them and thinking about their reliability.
|
||||
|
||||
More light will be shed on concepts rather than on setting up and configuring components like Loadbalancers to achieve scalability, availability and reliability of systems
|
||||
|
||||
## Training Content
|
||||
- Introduction
|
||||
- Scalability
|
||||
- High Availability
|
||||
- Fault Tolerance
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
So, how do you go about learning to design a system?
|
||||
|
||||
*” Like most great questions, it showed a level of naivety that was breathtaking. The only short answer I could give was, essentially, that you learned how to design a system by designing systems and finding out what works and what doesn’t work.”
|
||||
Jim Waldo, Sun Microsystems, On System Design*
|
||||
|
||||
|
||||
As software and hardware systems have multiple moving parts, we need to think about how those parts will grow, their failure modes, their inter-dependencies, how it will impact the users and the business.
|
||||
|
||||
There is no one-shot method or way to learn or do system design, we only learn to design systems by designing and iterating on them.
|
||||
|
||||
This course will be a starter to make one think about scalability, availability, and fault tolerance during systems design.
|
||||
|
||||
## Backstory
|
||||
|
||||
Let’s design a simple content sharing application where users can share photos, media in our application which can be liked by their friends. Let’s start with a simple design of the application and evolve it as we learn system design concepts
|
||||
|
||||

|
||||
|
||||
|
|
@ -0,0 +1,182 @@
|
|||
# Scalability
|
||||
What does scalability mean for a system/service? A system is composed of services/components, each service/component scalability needs to be tackled separately, and the scalability of the system as a whole.
|
||||
|
||||
A service is said to be scalable if, as resources are added to the system, it results in increased performance in a manner proportional to resources added
|
||||
|
||||
An always-on service is said to be scalable if adding resources to facilitate redundancy does not result in a loss of performance
|
||||
|
||||
## Refer
|
||||
- [https://www.allthingsdistributed.com/2006/03/a_word_on_scalability.html](https://www.allthingsdistributed.com/2006/03/a_word_on_scalability.html)
|
||||
|
||||
|
||||
## Scalability - AKF Scale Cube
|
||||
|
||||
The [Scale Cube](https://akfpartners.com/growth-blog/scale-cube) is a model for segmenting services, defining microservices, and scaling products. It also creates a common language for teams to discuss scale related options in designing solutions. Following section talks about certain scaling patterns based on our inferences from AKF cube
|
||||
|
||||
## Scalability - Horizontal scaling
|
||||
|
||||
Horizontal scaling stands for cloning of an application or service such that work can easily be distributed across instances with absolutely no bias.
|
||||
|
||||
Lets see how our monolithic application improves with this principle
|
||||
|
||||
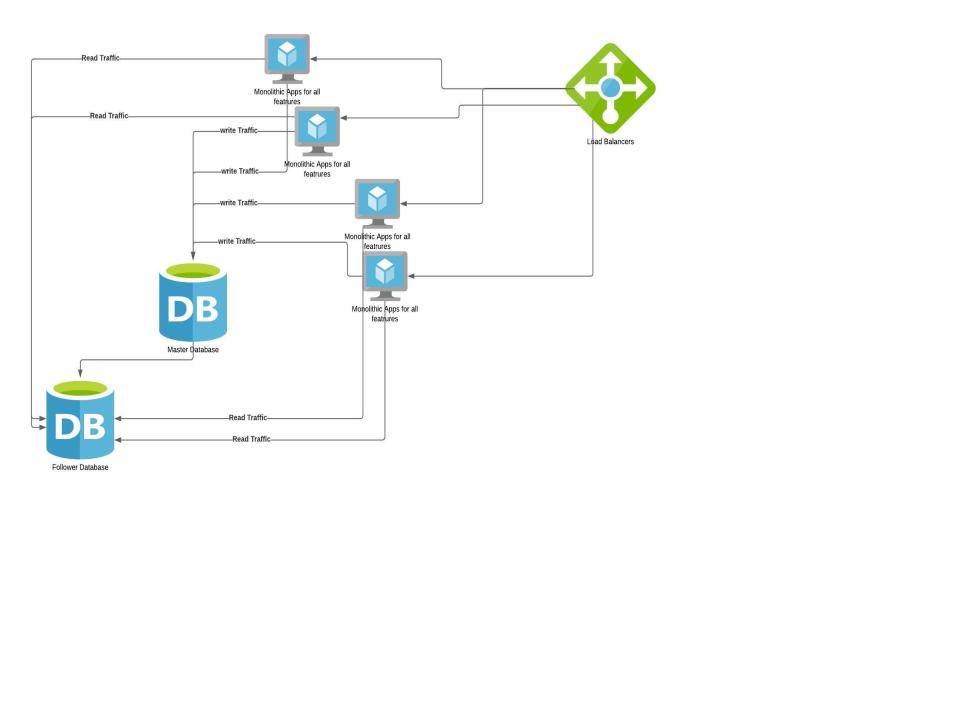
|
||||
|
||||
Here DB is scaled separately from the application. This is to let you know each component’s scaling capabilities can be different. Usually web applications can be scaled by adding resources unless there is no state stored inside the application. But DBs can be scaled only for Reads by adding more followers but Writes have to go to only one master to make sure data is consistent. There are some DBs which support multi master writes but we are keeping them out of scope at this point.
|
||||
|
||||
Apps should be able to differentiate between Read and Writes to choose appropriate DB servers. Load balancers can split traffic between identical servers transparently.
|
||||
|
||||
**WHAT:** Duplication of services or databases to spread transaction load.
|
||||
|
||||
**WHEN TO USE:** Databases with a very high read-to-write ratio (5:1 or greater—the higher the better). Because only read replicas of DBs can be scaled, not the Master.
|
||||
|
||||
**HOW TO USE:** Simply clone services and implement a load balancer. For databases, ensure that the accessing code understands the difference between a read and a write.
|
||||
|
||||
**WHY:** Allows for fast scale of transactions at the cost of duplicated data and functionality.
|
||||
|
||||
**KEY TAKEAWAYS:** This is fast to implement, is low cost from a developer effort perspective, and can scale transaction volumes nicely. However, they tend to be high cost from the perspective of the operational cost of data. Cost here means if we have 3 followers and 1 Master DB, the same database will be stored as 4 copies in the 4 servers. Hence added storage cost
|
||||
|
||||
### Refer
|
||||
- [https://learning.oreilly.com/library/view/the-art-of/9780134031408/ch23.html](https://learning.oreilly.com/library/view/the-art-of/9780134031408/ch23.html)
|
||||
|
||||
### Scalability Pattern - Load Balancing
|
||||
|
||||
Improves the distribution of workloads across multiple computing resources, such as computers, a computer cluster, network links, central processing units, or disk drives. Commonly used technique is load balancing traffic across identical server clusters. Similar philosophy is used to load balance traffic across network links by [ECMP](https://en.wikipedia.org/wiki/Equal-cost_multi-path_routing), disk drives by [RAID](https://en.wikipedia.org/wiki/RAID) etc
|
||||
|
||||
Aims to optimize resource use, maximize throughput, minimize response time, and avoid overload of any single resource.
|
||||
Using multiple components with load balancing instead of a single component may increase reliability and availability through redundancy. In our updated architecture diagram we have 4 servers to handle app traffic instead of a single server
|
||||
|
||||
The device or system that performs load balancing is called a load balancer, abbreviated as LB.
|
||||
|
||||
#### Refer
|
||||
- [https://en.wikipedia.org/wiki/Load_balancing_(computing)](https://en.wikipedia.org/wiki/Load_balancing_(computing))
|
||||
- [https://blog.envoyproxy.io/introduction-to-modern-network-load-balancing-and-proxying-a57f6ff80236](https://blog.envoyproxy.io/introduction-to-modern-network-load-balancing-and-proxying-a57f6ff80236)
|
||||
- [https://learning.oreilly.com/library/view/load-balancing-in/9781492038009/](https://learning.oreilly.com/library/view/load-balancing-in/9781492038009/)
|
||||
- [https://learning.oreilly.com/library/view/practical-load-balancing/9781430236801/](https://learning.oreilly.com/library/view/practical-load-balancing/9781430236801/)
|
||||
- [http://shop.oreilly.com/product/9780596000509.do](http://shop.oreilly.com/product/9780596000509.do)
|
||||
|
||||
### Scalability Pattern - LB Tasks
|
||||
|
||||
What does an LB do?
|
||||
|
||||
|
||||
#### Service discovery:
|
||||
What backends are available in the system? In our architecture, 4 servers are available to serve App traffic. LB acts as a single endpoint that clients can use transparently to reach one of the 4 servers.
|
||||
|
||||
#### Health checking:
|
||||
What backends are currently healthy and available to accept requests? If one out of the 4 App servers turns bad, LB should automatically short circuit the path so that clients don’t sense any application downtime
|
||||
|
||||
#### Load balancing:
|
||||
What algorithm should be used to balance individual requests across the healthy backends? There are many algorithms to distribute traffic across one of the four servers. Based on observations/experience, SRE can pick the algorithm that suits their pattern
|
||||
|
||||
### Scalability Pattern - LB Methods
|
||||
Common Load Balancing Methods
|
||||
|
||||
#### Least Connection Method
|
||||
directs traffic to the server with the fewest active connections. Most useful when there are a large number of persistent connections in the traffic unevenly distributed between the servers. Works if clients maintain long lived connections
|
||||
|
||||
#### Least Response Time Method
|
||||
directs traffic to the server with the fewest active connections and the lowest average response time. Here response time is used to provide feedback of server’s health
|
||||
|
||||
#### Round Robin Method
|
||||
rotates servers by directing traffic to the first available server and then moves that server to the bottom of the queue. Most useful when servers are of equal specification and there are not many persistent connections.
|
||||
|
||||
#### IP Hash
|
||||
the IP address of the client determines which server receives the request. This can sometimes cause skewness in distribution but is useful if apps store some state locally and need some stickiness
|
||||
|
||||
More advanced client/server-side example techniques
|
||||
- https://docs.nginx.com/nginx/admin-guide/load-balancer/
|
||||
- http://cbonte.github.io/haproxy-dconv/2.2/intro.html#3.3.5
|
||||
- https://twitter.github.io/finagle/guide/Clients.html#load-balancing
|
||||
|
||||
|
||||
### Scalability Pattern - Caching - Content Delivery Networks (CDN)
|
||||
|
||||
|
||||
CDNs are added closer to the client’s location. If the app has static data like images, Javascript, CSS which don’t change very often, they can be cached. Since our example is a content sharing site, static content can be cached in CDNs with a suitable expiry.
|
||||
|
||||
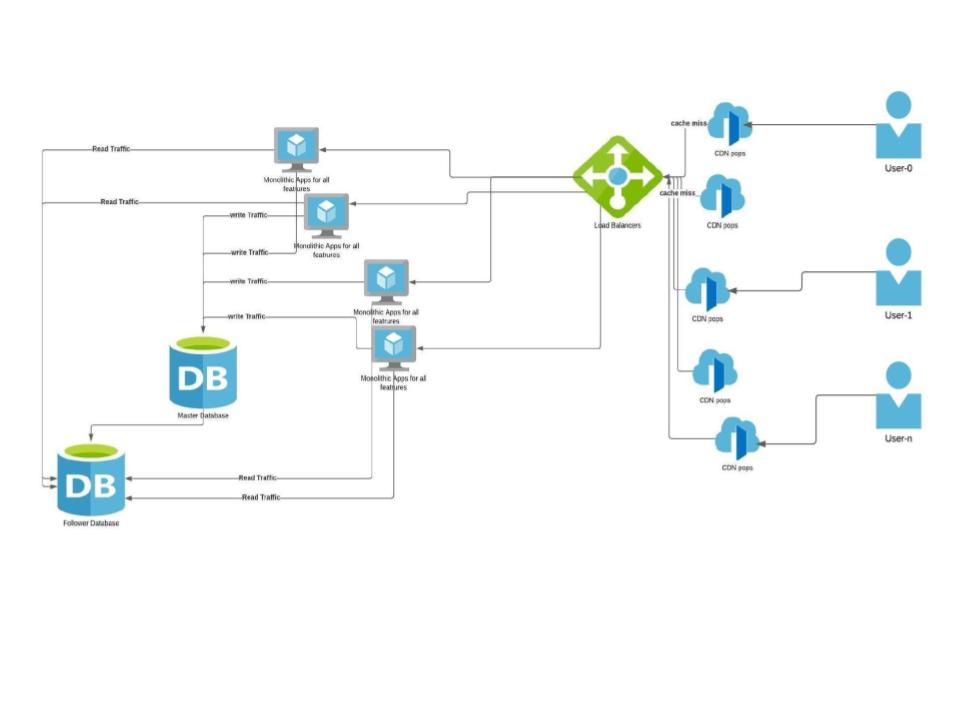
|
||||
|
||||
**WHAT:** Use CDNs (content delivery networks) to offload traffic from your site.
|
||||
|
||||
**WHEN TO USE:** When speed improvements and scale warrant the additional cost.
|
||||
|
||||
**HOW TO USE:** Most CDNs leverage DNS to serve content on your site’s behalf. Thus you may need to make minor DNS changes or additions and move content to be served from new subdomains.
|
||||
|
||||
Eg
|
||||
media-exp1.licdn.com is a domain used by Linkedin to serve static content
|
||||
|
||||
Here a CNAME points the domain to the DNS of CDN provider
|
||||
|
||||
dig media-exp1.licdn.com +short
|
||||
|
||||
2-01-2c3e-005c.cdx.cedexis.net.
|
||||
|
||||
|
||||
**WHY:** CDNs help offload traffic spikes and are often economical ways to scale parts of a site’s traffic. They also often substantially improve page download times.
|
||||
|
||||
**KEY TAKEAWAYS:** CDNs are a fast and simple way to offset the spikiness of traffic as well as traffic growth in general. Make sure you perform a cost-benefit analysis and monitor the CDN usage. If CDNs have a lot of cache misses, then we don’t gain much from CDN and are still serving requests using our compute resources.
|
||||
|
||||
|
||||
## Scalability - Microservices
|
||||
|
||||
This pattern represents the separation of work by service or function within the application. Microservices are meant to address the issues associated with growth and complexity in the code base and data sets. The intent is to create fault isolation as well as to reduce response times.
|
||||
|
||||
Microservices can scale transactions, data sizes, and codebase sizes. They are most effective in scaling the size and complexity of your codebase. They tend to cost a bit more than horizontal scaling because the engineering team needs to rewrite services or, at the very least, disaggregate them from the original monolithic application.
|
||||
|
||||
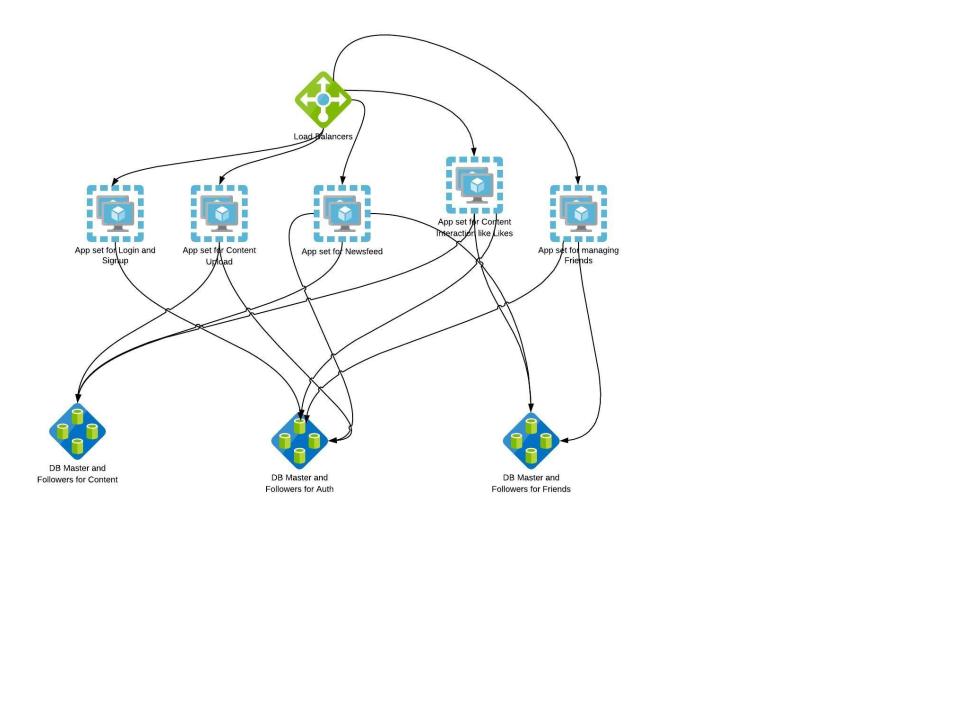
|
||||
|
||||
**WHAT:** Sometimes referred to as scale through services or resources, this rule focuses on scaling by splitting data sets, transactions, and engineering teams along verb (services) or noun (resources) boundaries.
|
||||
|
||||
**WHEN TO USE:** Very large data sets where relations between data are not necessary. Large, complex systems where scaling engineering resources requires specialization.
|
||||
|
||||
**HOW TO USE:** Split up actions by using verbs, or resources by using nouns, or use a mix. Split both the services and the data along the lines defined by the verb/noun approach.
|
||||
|
||||
**WHY:** Allows for efficient scaling of not only transactions but also very large data sets associated with those transactions. It also allows for the efficient scaling of teams.
|
||||
|
||||
**KEY TAKEAWAYS:** Microservices allow for efficient scaling of transactions, large data sets, and can help with fault isolation. It helps reduce the communication overhead of teams. The codebase becomes less complex as disjoint features are decoupled and spun as new services thereby letting each service scale independently specific to its requirement.
|
||||
|
||||
### Refer
|
||||
- https://learning.oreilly.com/library/view/the-art-of/9780134031408/ch23.html
|
||||
|
||||
## Scalability - Sharding
|
||||
|
||||
This pattern represents the separation of work based on attributes that are looked up or determined at the time of the transaction. Most often, these are implemented as splits by requestor, customer, or client.
|
||||
|
||||
Very often, a lookup service or deterministic algorithm will need to be written for these types of splits.
|
||||
|
||||
Sharding aids in scaling transaction growth, scaling instruction sets, and decreasing processing time (the last by limiting the data necessary to perform any transaction). This is more effective at scaling growth in customers or clients. It can aid with disaster recovery efforts, and limit the impact of incidents to only a specific segment of customers.
|
||||
|
||||

|
||||
|
||||
Here the auth data is sharded based on user names so that DBs can respond faster as the amount of data DBs have to work on has drastically reduced during queries.
|
||||
|
||||
There can be other ways to split
|
||||
|
||||
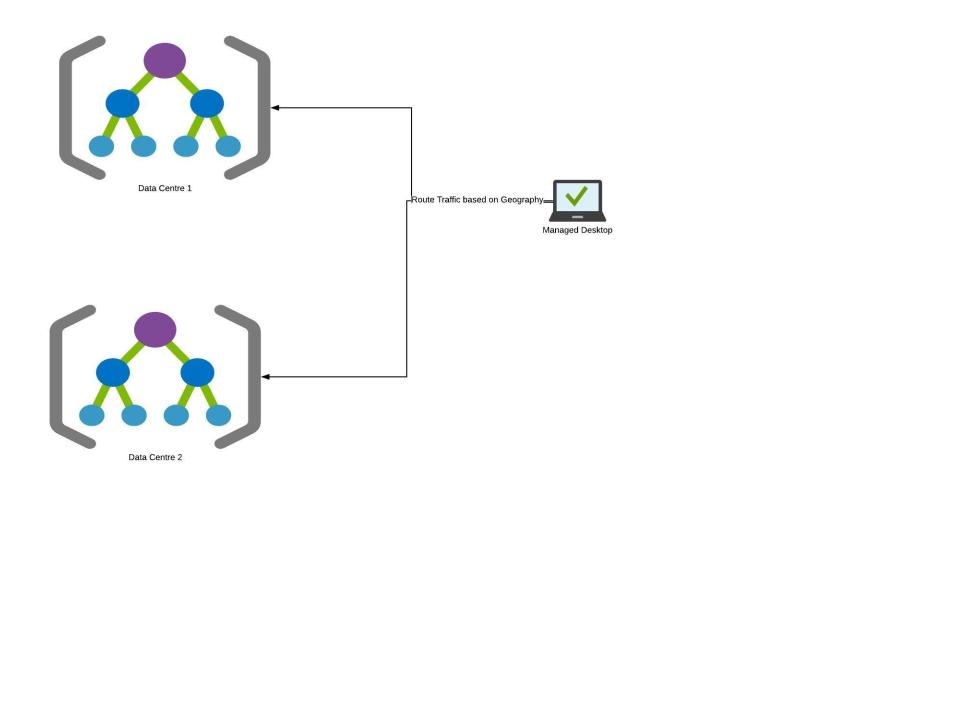
|
||||
|
||||
Here the whole data centre is split and replicated and clients are directed to a data centre based on their geography. This helps in improving performance as clients are directed to the closest Data centre and performance increases as we add more data centres. There are some replication and consistency overhead with this approach one needs to be aware of. This also gives fault tolerance by rolling out test features to one site and rollback if there is an impact to that geography
|
||||
|
||||
**WHAT:** This is very often a split by some unique aspect of the customer such as customer ID, name, geography, and so on.
|
||||
|
||||
**WHEN TO USE:** Very large, similar data sets such as large and rapidly growing customer bases or when the response time for a geographically distributed customer base is important.
|
||||
|
||||
**HOW TO USE:** Identify something you know about the customer, such as customer ID, last name, geography, or device, and split or partition both data and services based on that attribute.
|
||||
|
||||
**WHY:** Rapid customer growth exceeds other forms of data growth, or you have the need to perform fault isolation between certain customer groups as you scale.
|
||||
|
||||
**KEY TAKEAWAYS:** Shards are effective at helping you to scale customer bases but can also be applied to other very large data sets that can’t be pulled apart using the microservices methodology.
|
||||
|
||||
### Refer
|
||||
- https://learning.oreilly.com/library/view/the-art-of/9780134031408/ch23.html
|
||||
|
||||
|
||||
|
||||
## SRE Use cases
|
||||
1. SREs in coordination with the network team work on how to map users traffic to a particular site.
|
||||
https://engineering.linkedin.com/blog/2017/05/trafficshift--load-testing-at-scale
|
||||
2. SREs work closely with the Dev team to split monoliths to multiple microservices that are easy to run and manage
|
||||
3. SREs work on improving Load Balancers' reliability, service discovery and performance
|
||||
4. SREs work closely to split Data into shards and manage data integrity and consistency.
|
||||
https://engineering.linkedin.com/espresso/introducing-espresso-linkedins-hot-new-distributed-document-store
|
||||
5. SREs work to set up, configure and improve CDN cache hit rate.
|
||||
|
||||
Loading…
Reference in New Issue